Rust语言|深入解析Rust所有权机制
引入
周五下午,一个朋友和我说他们公司在 Rust 分享会上讲到了所有权、rc 和 refcell。当时我就吹了个牛,我说:“这对写 C 的我很好理解”。为了装完这个 X,周六周日连忙翻出了《Rust程序设计语言》、《Rust圣经》、《Rust程序设计》,对其中的所有权内容进行了阅读。这就是诞生这篇《深入解析 Rust 所有权机制》博客的原因。
在本篇博客中,将省略 fn main() {} 的模板代码,需要时将相应示例放入 fn main() {} 中,即可运行。
推荐阅读:文章主体内容在所有权系统、移动与克隆、函数传值与返回和 Rc 与 Arc:共享所有权,如果在阅读过程中遇到堆栈的疑问或者深拷贝和浅拷贝的疑问可再去参考阅读后两小节。
所有权系统
所有运行的程序都必须管理其使用计算机内存的方式。在计算机语言的不断演变过程中,出现了三种流派:
- 垃圾回收机制(GC):在程序运行时不断寻找不再使用的内存,典型代表:Java、Go、Python。
- 手动管理内存的分配和释放:在代码编写时,通过函数调用的方式来申请和释放内存,唯二代表:C、C++。
- 通过所有权来管理内存:编译器在编译时会根据一系列规则进行检查,典型代表:Rust。
在控制优先(手动管理内存的分配和释放)和安全优先(垃圾回收机制)之外设计的第三种 中庸之道(所有权管理内存),解决安全优先语言的性能损失问题和控制优先语言的不安全问题,从而编写出既安全又高效的程序。
有人说,Rust 会增加编写代码时的心智负担,但在我看来简单结构的确会增加了一些非必要的心智负担,但是复杂结构会大大降低你编写代码时的心智负担。
所有权规则
在下面的文章中,我们将会深入去理解 Rust 的所有权规则,其规则如下:
- Rust 中的每一个值都有一个被称为其 所有者(owner) 的变量。
- 值在任意时刻有且仅有一个所有者。
- 当所有者(变量)离开其作用域时,这个值将被丢弃。
变量作用域
作用域是一个变量在程序中有效的范围。
1 | { // s 在这里无效,因为它此时尚未声明 |
将 String 类型 “hello” 绑定到变量 s 上,s 就作为了 String 类型 “hello” 的所有者。当 s 变量离开作用域,Rust 会自动调用一个特殊的释放内存的 drop() 函数,这种释放的行为也被称为 丢弃(drop)。
所有权树
一个拥有一个值的所有者,可以很容易地决定何时丢弃它,但是一个拥有多个值,并且每个值可能会拥有许多其它值的所有者呢?
1 | struct Person { name: String, birth: i32 }; |
composers 在内存中的表示如下:
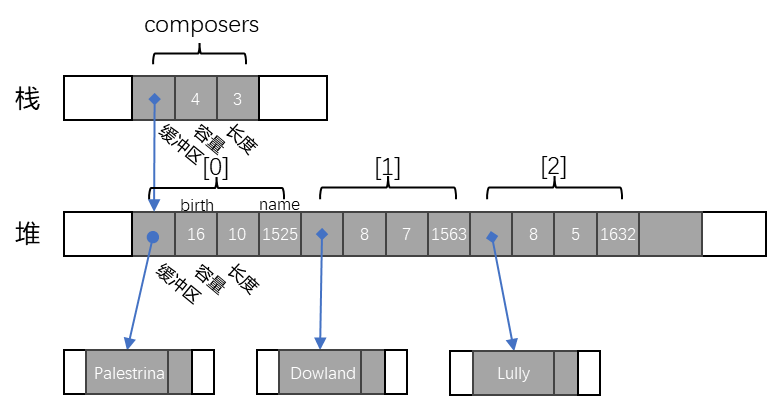
composers 中的每个元素都各自拥有一个字符串,该字符串又拥有自己的文本。所有者及其拥有的那些值形成了一棵树,这颗树就是 所有权树。
值的所有者是值的父节点,值所拥有的值是值的子节点。每棵树的总根都是一个变量,当该变量超出作用域时,整棵树都将随之销毁。
移动(move)与克隆(copy)
转移所有权
Rust 中的基本数据类型,包括所有的机器整数类型、浮点数类型、char 类型、bool 类型,以及 Copy 类型的元组或固定大小的数组进行赋值时会复制整个值。例如:
1 | let x = 5; |
将 5 绑定到变量 x,接着拷贝 x 的值赋给 y,最终 x 和 y 都等于 5。
而对于涉及到向量、字符串和其它可能占用大量内存且复制成本高昂的类型,在进行赋值时则使用移动语义。例如:
1 | let s1 = String::from("hello"); |
将 s1 对 String 类型 “hello” 的所有权移动到了 s2 身上,之后 s1 不再指向任何数据,只有 s2 是有效的。当 s2 离开作用域时,会释放内存。
移动(move)
在 Rust 中对大多数类型,像为变量赋值、将其传给函数或从函数返回这样的操作都不会复制值,而是会移动值。值的源会把值的所有权转移给目标并变回未初始化状态,改为目标变量来控制值的生命周期。举例:
1 | let s = vec!["udon".to_string(), "ramen".to_string(), "soba".to_string()]; |
纯字符串字面量(如,”udon”)存储在栈中,而为了清晰地说明移动语义,调用 to_string() 方法以获取堆上分配的 String 值。
该赋值操作在内存中的表示如下:
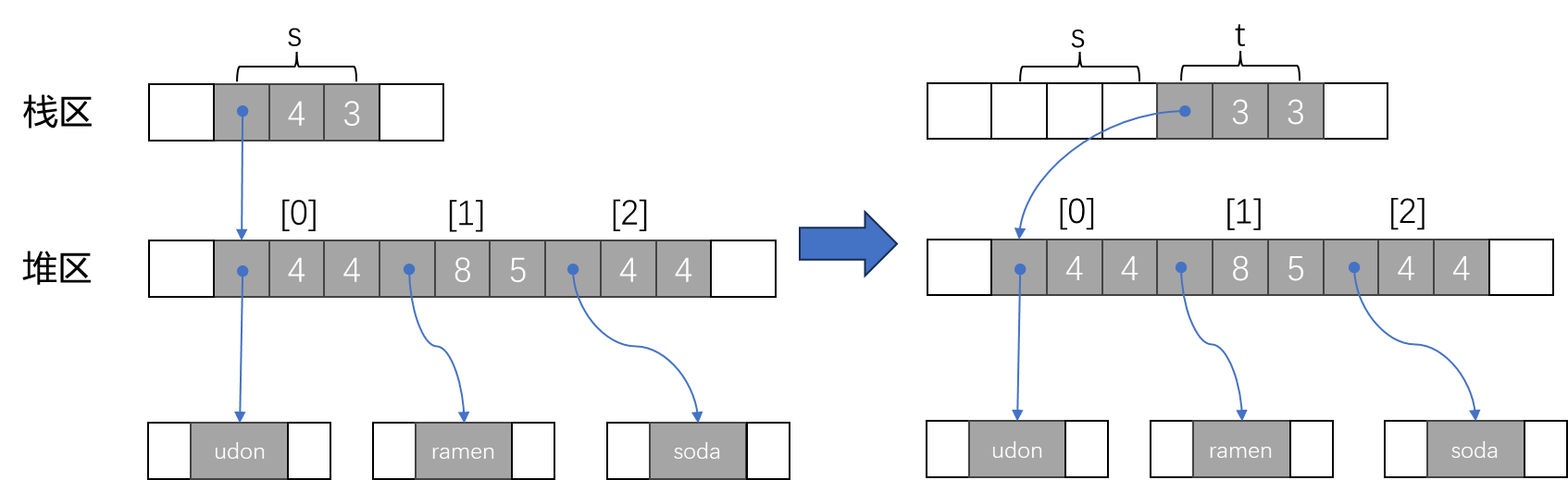
初始化语句 let t = s; 将向量的 3 个标头字段从 s 转移给了 t,现在 t 拥有了该向量的所有权,s 则变回了未初始化状态。
如果此时我们再执行 let u = s;,编译器会拒绝执行此代码并报出如下错误:
1 | error[E0382]: use of moved value: `s` |
按照编译器报错提示,如果想要显式地同时访问 t 和 s,必须显式地进行复制,Rust 提供 clone() 方法,该方法会执行向量及其元素的深拷贝。
1 | let s = vec!["udon".to_string(), "ramen".to_string(), "soba".to_string()]; |
这一段推荐阅读《Rust程序设计》的 4.2 节移动,会清晰地讲解从 Python 到 C++ 再到 Rust,赋值操作的差异以及该设计的原因。
克隆(copy)
对整数或字符这样的简单数据类型,在编译时是已知大小的,会被存储到栈上,再进行如此谨小慎微地移动处理实在没有必要。Rust 中有一种叫做 Copy 的 trait,可以用在此类简单数据类型的处理。
举例,比较 copy 和 move 的差异:
1 | let string1 = "hello".to_string(); |
这段代码在内存中的表示如下:
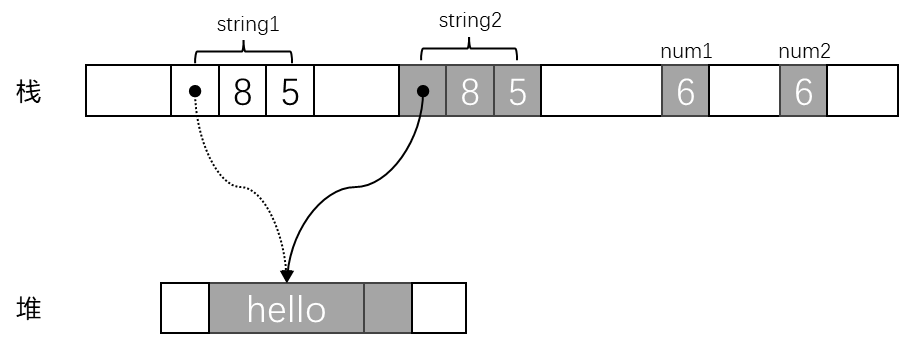
赋值会将 string1 的所有权转移给 string2,这样就不会出现两个字符串放在同一个缓冲区的情况。但是 num1 和 num2 的情况则有所不同,i32 只是内存中的 4 个字节,它不拥有任何堆上的资源,也不会依赖除自身字节之外的任何内存。因此当将 num1 赋值给 num2 时,其实是为 num2 制作了一个完全独立的副本。
以下是具有 copy trait 的类型:
- 所有的整数类型,如 i32。
- 布尔类型 bool,true or false。
- 所有的浮点数类型,如 f64。
- 字符类型,char。
- 元组,当且仅当其包含的类型也都是具有 copy trait 的时候,如 (i32, i32) 是 copy 的,但是 (i32, String) 不是 copy 的。
- 不可变引用 &T。
函数传值与返回
函数传值
将值传递给函数,一样会发生 move or copy,至于具体发生 move 还是 copy 则取决于传入的值本身的 trait。举例:
1 | fn main() { |
返回值
返回值也可以转移所有权。
1 | fn main() { |
Rc 与 Arc:共享所有权
在以上典型的 Rust 代码中,大多数值都会拥有唯一的所有者,然而某些情况下我们希望某个值存续到每个人都使用完它,Rust 提供了引用计数指针类型 Rc 和 Arc。
其中 Arc 可以安全地在线程之间直接共享,而 Rc 使用更快的非线程安全代码来更新其引用计数。
考虑以下代码:
1 | use std::rc::Rc; |
对于任意类型 T,Rc<T> 值是指向附带引用计数的在堆上分配的 T 型指针。克隆一个 Rc<T> 并不会复制 T,相反它只是创建另一个指向它的指针并递增引用计数。该代码在内存中的效果如下:
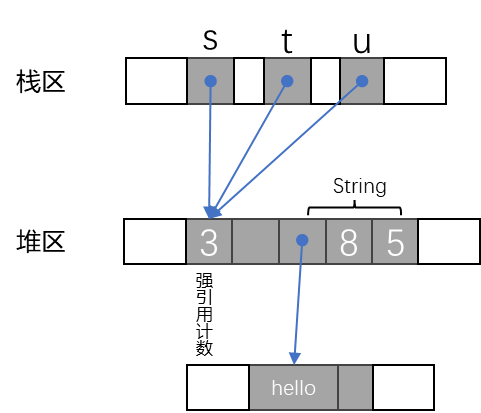
这三个 Rc<String> 指针指向了同一块内存,其中包含引用计数和 String 本身的空间。所有权规则适用于 Rc 指针本身,当丢弃最后一个现有 Rc 时,Rust 也会丢弃 String。
栈(Stack)和堆(Heap)
在多数语言中,并不需要经常考虑栈和堆。然而在 Rust、C、C++ 这类的系统编程语言中,值是位于栈区还是位于堆区很大程度上影响了语言的行为以及为什么要做出这样的选择。
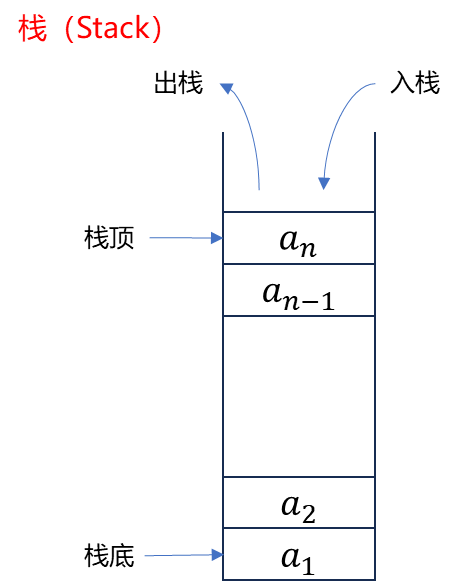
栈(Stack)
栈:由编译器自动分配和释放的区域,主要存放函数的参数值、局部变量的值等。
栈按照顺序存储值并以相反顺序取出值,我们可以将栈类比为桌面上的一摞盘子。如果需要增加更多盘子,则把新增盘子放在桌面盘子堆的顶部;当需要盘子时,则从顶部拿走。不能从中间或者底部增加和拿走盘子。这也被称作 后进先出(last in, first out)。
增加数据叫做 进栈(pushing onto the stack),移出数据叫做 出栈(popping off the stack)。
堆(Heap)
堆:由程序员手动分配和释放的内存区域,主要存放大小未知或可能变化的数据。
堆上数据的存取是缺乏组织的。当需要请求一定大小的内存空间,操作系统会在堆的某处找到一块足够大的空位,把它标记为已使用,并返回一个表示该位置地址的指针(存储到栈上),该过程称之为在堆上分配内存,简称 分配(allocating)。
将堆上分配内存类比为到餐馆吃饭,进入餐馆时,告知服务员一行有几个人,然后服务员会在餐馆内找到一个足够大的空桌子并领你们过去(堆上分配的内存空间),其中的桌号(栈上的指针)可以用来找到你们。
栈和堆的比较
写入方面:
入栈比在堆上分配内存要快,因为入栈时操作系统无需分配新的空间,只需将新数据放入栈顶即可。相较之下,在堆上分配内存则需要做更多的工作,操作系统首先要找到一块足够存放数据的内存空间,接着做一些记录为下一次分配做准备。
读取方面:
得益于 CPU 的高速缓存,使得处理器可以减少堆内存的访问,高速缓存的内存的访问速度差异在 10 倍以上!栈数据往往可以直接存储在 CPU 的高速缓存中,而堆数据只能存储在内存中。因此,访问堆上的数据比访问栈上的数据要慢,也因为必须先访问栈,再通过栈上的指针来访问内存上的数据。
深拷贝(克隆)和浅拷贝(拷贝)
浅拷贝
浅拷贝:浅拷贝复制的是对象的引用地址,并没有开辟新的栈。只是对原对象的“引用”进行复制,而不是对整个对象进行复制。
浅拷贝的结果是两个对象指向同一个地址,任何对其中一个对象的属性做出的修改,都会影响到另一个对象。
深拷贝
深拷贝:深拷贝会创建一个新的对象,并且不会与原对象共享内存。这意味着深拷贝要把复制的对象所引用的对象都复制一遍。
深拷贝的结果是两个对象指向两个地址,对新对象的修改不会影响到原对象。
深拷贝和浅拷贝的对比
深拷贝和浅拷贝的示意图如下:
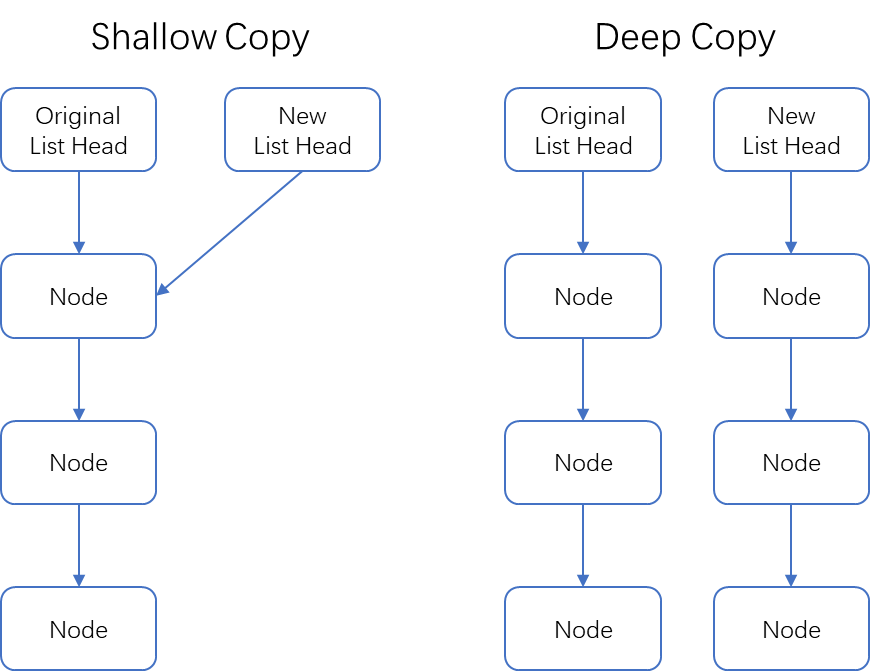
浅拷贝只发生在栈上,因此性能很高。而深拷贝不仅仅要复制栈上的数据,还要深度复制堆上的数据,因此对性能影响较大。
总结
本文对 Rust 的所有权机制进行了深入的分析,参考了《Rust程序设计语言》、《Rust圣经》、《Rust程序设计》这三本书上的内容,并进行了一定的改写和重组以达到更好的理解效果。如果在阅读的过程中产生别的疑惑,可在下方评论处留言或者通过公告加我的微信进行私下讨论。
 wechat
wechat- alipay



